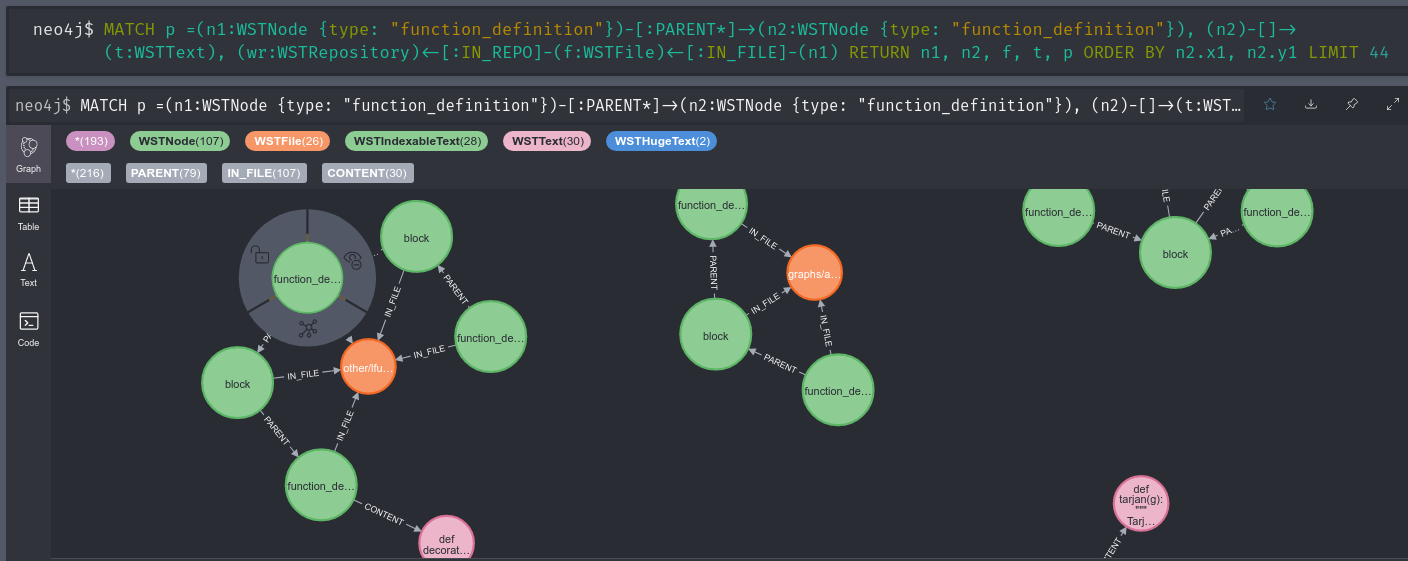
I recently proposed a new research project idea: let’s take all of GitHub (or <insert your preferred VCS host>) and create a multi-language (even partially language-agnostic) concrete syntax tree of all the code so that we can do some otherwise impossibly difficult further research and answer incredibly complex questions.
This project is named World Syntax Tree, or WST in short.
Originally I started the project using MongoDB and storing references between nodes as ObjectIDs, but I quickly realized that a tabular format was not performant enough to be able to effectively represent a true tree.
So instead I switched over the whole project to the first and foremost graph database I came across: Neo4j.
As I quickly learned the new database paradigm I also quickly learned that there are a lot of problems between me and inserting literally hundreds of terabytes of data into a single graph…
The initial (reference) collector design
The very first designs used neomodel to control the layout and define the graph connections, and in fact we still use neomodel for the less performance-sensitive parts of the collection process.
After running with neomodel for a fairly long time it was obvious it was far too much overhead when I inspected the collector process with cProfile and snakeviz.
Using neomodel there were more than twice as many required queries for simply inserting one syntax node (WSTNode), extra checks like Cardinality and multiple statements just to set properties on newly created nodes were quite slow: at best I found I could insert a few hundred nodes per second using 128 processes.
Dropping the OGM
From just the first few google results it was clear that writing my own raw cypher queries was the next move in order to better control exactly what operations needed to happen.
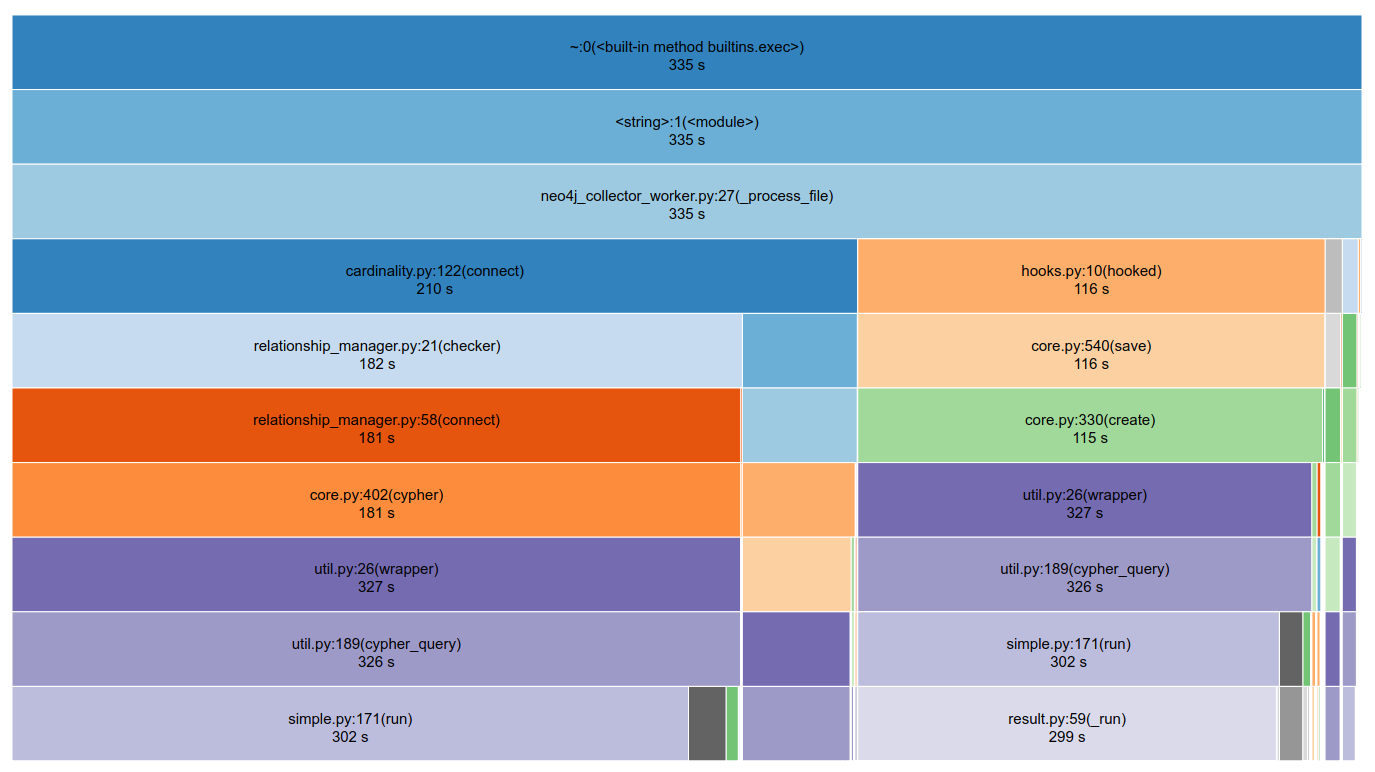
The next PR that came from these efforts reworked the WSTNode creation routine into a series of functions that each did a distinct task: create the node, connect the node, add the node text, connect the node text, etc.
This did improve compared to using neomodel, but now the major bottleneck was really waiting on the network socket.
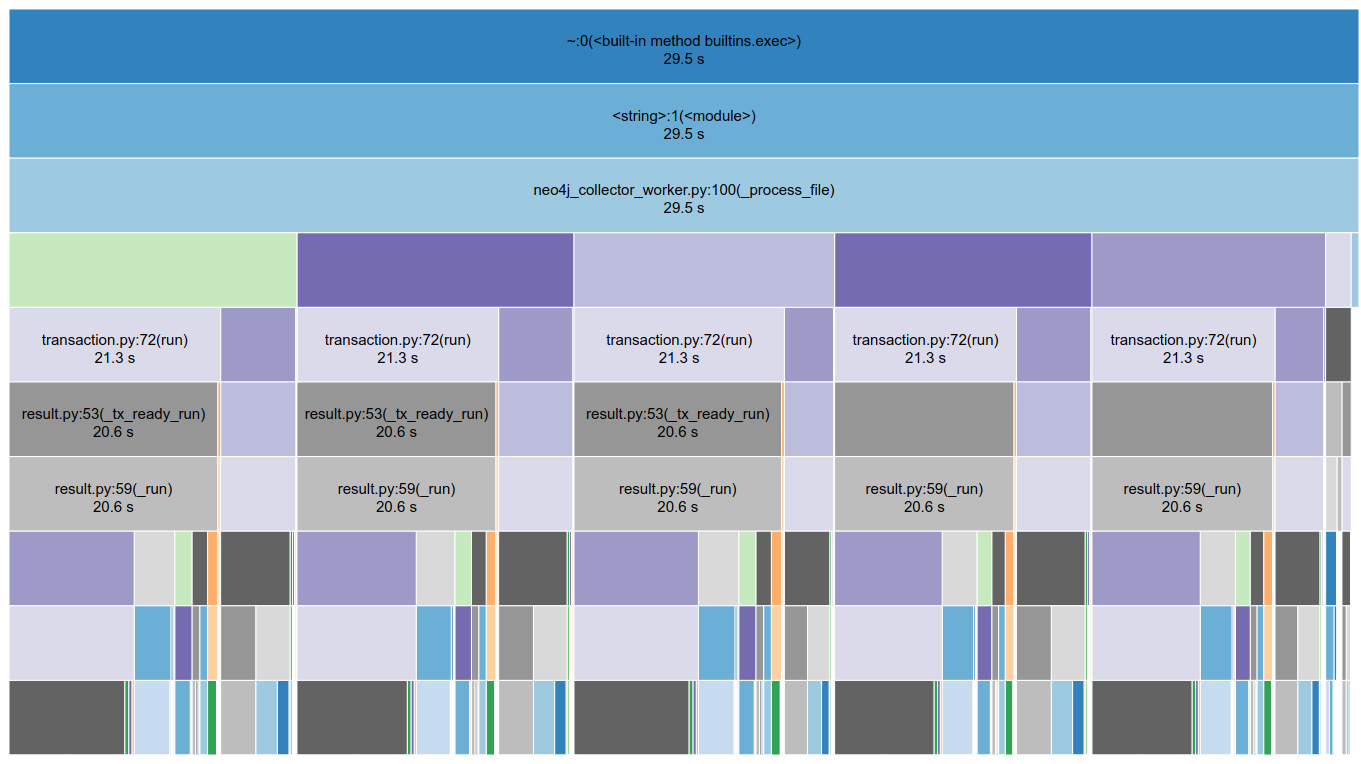
Each of those 5 blocks corresponds to one of the 5 functions used during insertion of a WSTNode, noticing how they were all approximately the same size led me onto my next improvement…
Combining and refactoring Queries
Once I saw how long each query took to initialize a connection and read back the results I figured I should reduce the total number of queries, which was quite easy really.
Instead of creating a node, returning the ID, running a new query to connect using that ID… just rewriting the create query to connect the new node as well meant an entire query less to execute!
So now that we reduced the number of calls made per node by more than half we saw a reasonable improvement, but we’re still only talking about a few hundred nodes per second even with more than a 100 workers.
Batching multiple nodes per query
Now we’re at the difficult part of the problem. Because we’re inserting a collection of nodes that refer to each other, we can’t iterate them all in parallel, otherwise some nodes might not have their parent node written to the database yet.
So in order to do this I needed to add another property to the WSTNode structure: preorder. This property was unique for nodes within a file and is calculated before we insert the WSTNode into the database, meaning we can use this property to refer to nodes before they are given a node ID by neo4j.
Once we have a way to refer to nodes uniquely within the file we can batch together large numbers of node insertions by using the super-magical UNWIND cypher statement. Essentially this allows us to pass a huge query parameter (like 10,000 node’s worth of properties in a list) and execute a single query to create those 10,000 nodes.
Indexes are not enough to perform efficient lookups
If any experienced Neo4j user has followed along so far, they might have already realized that the preorder property on my WSTNodes is not unique within the graph, so even though we do have an index on that property, when your graph grows to terabytes in size, you will have far too many nodes with the same preorder to efficiently search them all to find the one that has a relationship to the same WSTFile node we’re working in.
Because of this single extra condition inside the WHERE clause the Neo4j database regularly would pin all 128 hardware threads of our lab server just searching through WSTNodes with the same preorder just to find the one that has a relationship to our WSTFile.
So instead I needed a way to refer to the nodes I just created with a constant-time lookup. I spent a whole day just thinking about how to overcome this problem, and finally ended up just accepting the fact that it would be faster to just execute two queries rather than continue banging my head against cypher syntax quirks.
After the first query I use the returned created node IDs to do the constant-time relationship creation in the second query. There might be some way to create relationships based on results from an UNWIND, but as long as we’ve got constant-time inserts on the db side I am happy.
And it was indeed faster:
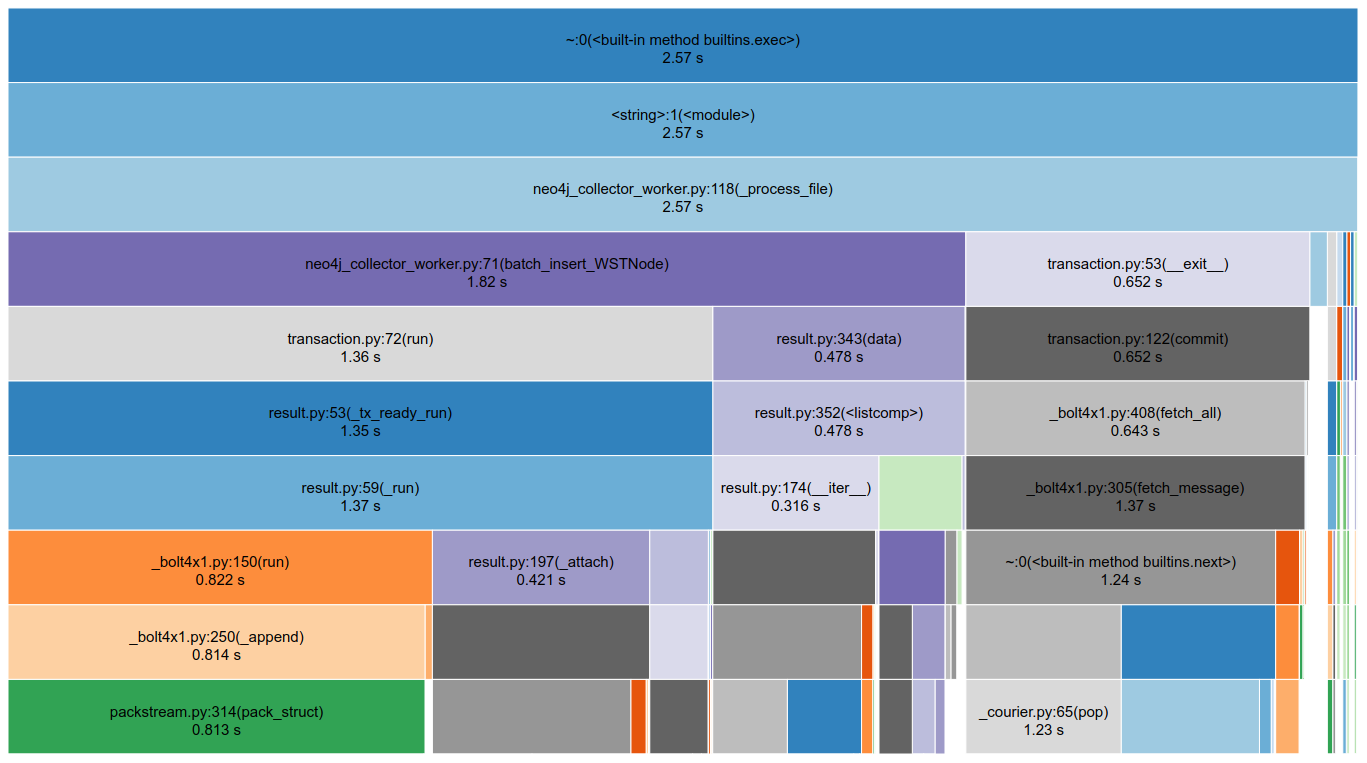
How’s that for performance improvement? We went from 330 seconds to under 3! Of course, 330 seconds for a single file was kind of absurd in the first place.

Now that my program was blazing fast, Neo4j has trouble keeping up:
Not my problem(s)
These are problems I encountered outside the scope of my own program.
Too many transactions in memory
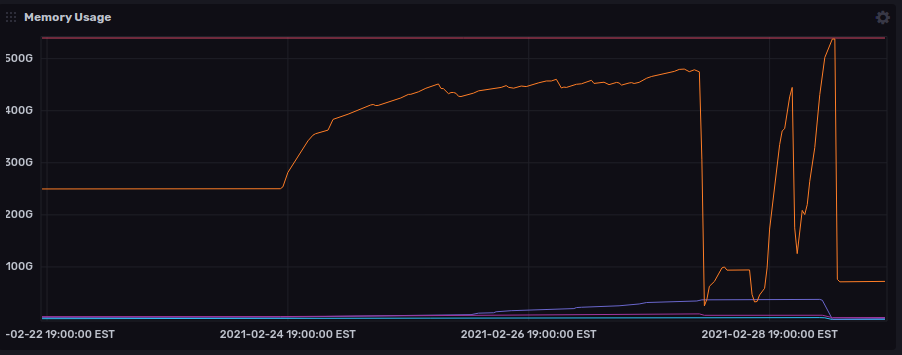
My initial guess for large batch sizes was around 10,000 nodes per query, however when we multiply that by 128 (processes running in parallel) and a conservative estimate for RAM usage, we’re looking at trying to processes transactions in memory at multiple gigabytes per second.
The solution to this was to manually set the memory settings in neo4j.conf, since I have a fairly large system dedicated to research work I could steal quite a bit of memory:
# Settings from memrec had to be changed a bit vs what was recommended:
# I need at least 128G left over for my own code to run on the same system
dbms.memory.heap.initial_size=31g
dbms.memory.heap.max_size=128g
dbms.memory.pagecache.size=259500m
# It is also recommended turning out-of-memory errors into full crashes,
# instead of allowing a partially crashed database to continue running:
dbms.jvm.additional=-XX:+ExitOnOutOfMemoryError
Database not up to the requested version
neo4j.exceptions.TransientError: {code: Neo.TransientError.Transaction.BookmarkTimeout} {message: Database 'top1k' not up to the requested version: 113071. Latest database version is 113054}
This is a tricky one, I still haven’t fully pinned down the exact conditions for this to happen, but it boils down to the database not applying the transactions in a timely manner, meaning the current “live version” could be more than a few transactions out of date. (With my scale of data it ranged from 5-20 versions out of date.)
The best solution I could come up for this problem was to only run half as many worker processes, my guess is that the database was having trouble handling 128 consecutive transactions at a time.
I’d like to know why exactly this happens, and if possible I would much rather prefer the query to stall until the requested version is met (or error the original query if that version can’t be reached) rather than fail a query later on.
If you happen to know something about why or how this happens, please leave a comment, email me, or even open an issue on our project!
A persistent problem
I thought if I reduced the load on the database significantly it would have no problem keeping up, so I brought the batch size down to just 100 and ran only 8 processes, and yet we still arrive at the same problem:
Database ‘top1k’ not up to the requested version: 2282021. Latest database version is 2282020
Why is my database stuck in 2020 you ask? Not a clue, so this is really where the adventure begins.
Over the few days since initial release of this post, I have been trying nothing but to get to the bottom of why this is occuring, I have carefully picked through both the neo4j debug.log and query.log and nothing really stood out as a problem.
One thing notable about these errors is they always seem to happen after passing around ~250GB of data stored. The most I could store before being stopped by this error was ~319GB (uncompressed) in the neo4j data directory. There are only ~500 million nodes and ~1.7 billion relationships at this point, meaning the average inserted node was well under a kilobyte, all within reason.
I can definitively confirm that there’s no problem with the hardware, the data directory is stored on a RAIDZ (zfs) array of all SSD storage, and I’ve confirmed that I/O time is not the bottleneck, and there are over 50 unused CPU cores to spare.
So my thoughts now are that the insert time for these nodes might not actually be constant as I thought, otherwise we’d see the same behavior between millions of nodes and just a few thousand. Perhaps there’s nonlinear work being done in some of the indexes? Maybe the data is too large to be indexed fully? There are a number of reasons to test, so finding the real cause will take quite a bit of time.